Simulating a Reddit Thread using BERT and GPT2
It is a great time to follow the trends and research in natural language processing (NLP). Every other day researchers publish new model architectures and techniques which try to improve the current state-of-the-art (SOTA) models. However, even though there is an abundance of different architectures and methods, almost all of these are based on 2 main ideas - Attention Models and the Transformer Architecture. These two ideas revolutionized the field of NLP when they were introduced a few years ago and pioneered the age of language models.
With respect to this, one of the most famous language models is Google's Bidirectional Encoder Representations from Transformers (BERT) and OpenAI's Generative Pre-trained Transformers (GPT) - both of which are based on the transformer architecture I mentioned previously. For a more detailed explanation of how these models work you can refer to these amazing blog posts - https://jalammar.github.io. After reading about the amazing results of these models and their applications, I decided to work on a personal data science project utilising some of these models, as part of a semester long capstone project in my graduate curriculum.
The Idea
I am big fan of Reddit and spend quite a good amount of time on subreddits like r/machinelearning, r/stocks, r/datascience etc… However, it is also a gold mine for NLP researchers and enthusiasts because it is perhaps the largest available repository for actual human conversations and can be of immense help for the new language models. We decided to use the openly available Reddit data and train language model on it to try and simulate a Reddit thread - where the model would get a Reddit post as input and will produce a bunch of comments mimicking real Reddit users.
Note that this is not a new thing and people have already trained GPT2 models on data for different subreddits to create artificial bots that create entire posts on their own and also fill in the comment sections (Link). Although achieving their intended purpose, a big issue with these bots is that they are trained to simulate comments/posts for just a single subreddit. For example, r/datasciencebot will be trained on only posts and comments relating to the r/datascience subreddit and can only produce results tailored specific to that subreddit. Try to generate data for, say, r/GameofThrones and it will go haywire. This is very different from humans who read a post, identify the underlying topic and then write comments specific to that topic/post.
Due to this reason, we took up the challenge of using only a single model for our project - a single model which can adapt to different topics and questions, identify what is being talked about and then generate comments/replies pertaining to that specific topic.

Example Model Input
→

Example Model Output
Getting the Data
A very huge dataset for Reddit is currently hosted on BigQuery and that is where we turned to for getting the appropriate data. Only two tables were required:
Reddit Comments
Data Size: 200 GB (01/2019 - 08/2019)
Number of Rows: 300 million (approx.)
Columns: 13 (final preprocessed columns)
Reddit Posts
Data Size: 100 GB (01/2019 - 08/2019)
Number of Rows: 100 million (approx.)
Columns: 13 (final preprocessed columns)
You can see that only a year of data is used and it is already of enormous size. All interactions with the data was done using SQL queries in BigQuery. For simplicity (and to meet the project deadlines!), data for only the following 9 subreddits was selected:
r/gameofthrones
r/showerthoughts
r/unpopularopinion
r/worldnews
r/soccer
r/funny
r/teenagers
r/politics
r/machinelearning
Data Columns Used
The following features were selected for the two data tables:
| created_utc | Time at which post was created |
| subreddit | The subreddit in which this post was posted |
| author | The author of this post |
| url | The URL of this post |
| num_comments | Number of comments in this post |
| score | Score of the post |
| title | Title of the post |
| selftext | Extra text below the post title |
| id | Unique id of the post |
| over_18 | Whether the post is over 18 or not |
| subreddit_id | Unique subreddit id |
| created_utc | Time at which the comment was posted |
| subreddit | The subreddit in which this comment was posted |
| author | The author of this comment |
| body | The text of this comment |
| name | Title of the post in which this comment was written |
| score | Score of the post |
| link_id | The URL link for this comment |
| id | Unique id of the comment |
| subreddit_id | Unique subreddit id |
Reddit Comments Table
Reddit Posts Table
Getting Insights from the Data
A lot of interesting insights were discovered which helped us later during the feature engineering stage. Due to such large amounts of data, we used Google Cloud Platform and it’s $500 free credits to our advantage. Some of the interesting plots are displayed below and we used plotly to create these interactive charts. For the purpose of this blog, I am not using the interactive charts but the respective code can be downloaded from my Github.
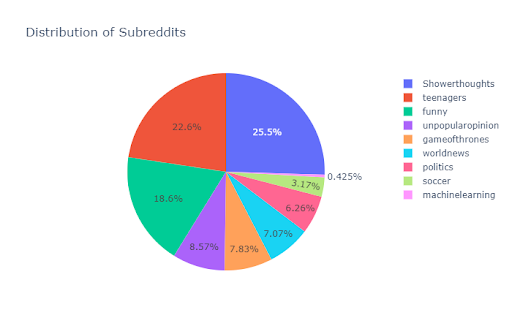
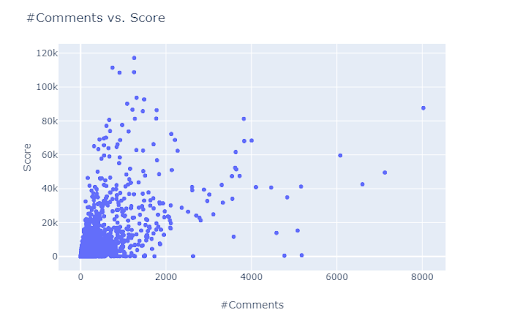

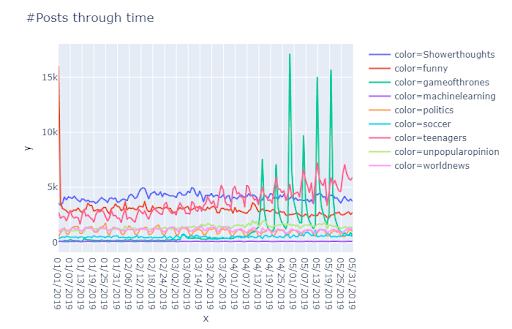



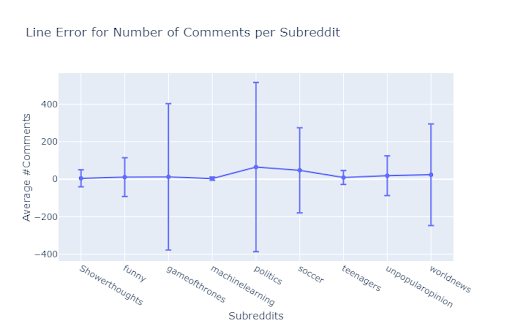

Some useful insights gained from the data exploration:
“Showerthoughts” has the highest percentage of posts
Posts through time show interesting trend for “gameofthrones” subreddit
Most of the posts have very few comments and scores.
1:00 PM to 5:00 PM is the rush hour!
Words are an important metric in segregating subreddits.
Some problems faced during this stage:
The sheer amount of data made the data exploration process very slow and time-consuming.
A lot of the plots were skewed, as can be seen from the two histograms above.
Modeling and Training
Due to our decision to keep a single model for generating comments and make it understand the topic (subreddit) of the input, two different types of models were used -
Classification Model :
Models: XGBoost, Vanilla Neural Networks, BERT


For the classification model, we considered some base models to generate a baseline and then used BERT as our final model as it clearly outperformed the base models’ performance (as expected!). For the base models, we tried using different features as shown in the above image but for BERT, just passing the raw title text was enough!
Language Generation Model :
Models: 124M GPT2

Before I explain how the classification model’s predictions are used to train the language model, we need to understand the input format for GPT2. One of the amazing things about GPT2 architecture is that it requires a simple text file as an input. However, this text file needs to be preprocessed before feeding it to the model. The following image shows a snippet of the file I used for training the model on Reddit data:

All language models require tokens specifying the beginning of a sentence <BOS> and end of a sentence <EOS>. I will not go into the specifics of why and how these tokens are used but merely provide details regarding how I used these tokens to create the training data pertaining to Reddit. For my use-case, it was important that the model should understand the beginning of a Reddit post as well as the beginning of the relevant comments to that post. From the above image:
****S : Indicates the beginning of a Reddit submission/post.
t5_2szyo : A unique ID indicating the subreddit of the post - from one of the 9 subreddits selected earlier. This token helps the model to learn the common types of words which follow a certain subreddit post. For e.g. a post in the r/machinelearning subreddit will have higher probability of having words like data science, linear regression, statistics etc..
****ES : Indicates the end of the Reddit submission/post.
abcujo : A unique ID for the submission/post.
***TC : Indicates the beginning of a top-level comment for the respective post. You can have hierarchies of comments on Reddit with multiple comments for a post and lots of replies/comments for a comment itself. To keep it simple, we only decided to use the top level comments - those comments at the top of the comment tree and directly replying to the post.
abcujo : For every comment for a post, we place the unique post ID next to the beginning of that comment. This tells the model, that the comment is replying to the submission/post with this ID.
****ETC : Indicates the end of the particular top-level comment.
In this way we keep adding the relevant Reddit data from our database into the text file - by encapsulating the posts between ****S and ****ES tags and the top level comments for each post between ****TC and ****ETC tags and at the same time, indicating the subreddit in which this post was created.
Combining Both the Models :
At this point, you may be wondering how and where do we incorporate the prediction of our classification model into this setup. The classification model predicts the subreddit for a post which is converted to the respective unique ID and then placed into the text file beside the ****S tag for the respective post.
Classification Model → Subreddit → Unique Subreddit ID → Text File → GPT2
We think that such a method removes the need for training multiple language models - each for a particular topic/subreddit. The classification models predict the type of subreddit, which is then placed beside the post tags in the text file. A language model will finally be able to learn what types of words follow a subreddit ID, extract the type of topic and produce comments relevant to the post. This is based on our assumption that the occurence of certain words is highly specific to the subreddit of the post e.g. a post in r/gameofthrones would have high probability of containing words like “Greyjoy”, “Stark”, “Lannister” and similarly an r/statistics post would have words like “p-value”, “R-squared” etc..
Training the Models :
The model training was done using GPU instances from Google Cloud.
System Specs: 30GB RAM, 8 core CPU, single P100 16GB GPU
It took 12 hrs to fine-tune the classification model and 5 hours for the language generation model.
Deploying the Models
Trained models were packaged into docker a container and deployed as a web API using cloud instances.

You can have a look at the code below:
import warnings
warnings.filterwarnings("ignore", category = FutureWarning)
from DistilBERT.model import DistilBERTModel
from GPT2.model import GPT2Model
from starlette.applications import Starlette
from starlette.responses import UJSONResponse
import uvicorn
import gpt_2_simple as gpt2
import tensorflow as tf
import os
import gc
# Initialise starlette app
app = Starlette(debug = True)
# Load pre-trained GPT2 Model
sess = gpt2.start_tf_sess(threads = 1)
gpt2_model = GPT2Model(tf_sess = sess)
gpt2_model.load_pretrained_model()
# Load pre-trained BERT Model
bert_model = DistilBERTModel()
bert_model.load_pretrained_model()
# Needed to avoid cross-domain issues
response_header = {
'Access-Control-Allow-Origin': '*'
}
generate_count = 0
@app.route('/', methods = ['GET', 'POST', 'HEAD'])
async def homepage(request):
global generate_count
global sess
global gpt2_model
global bert_model
if request.method == 'GET':
params = request.query_params
elif request.method == 'POST':
params = await request.json()
elif request.method == 'HEAD':
return UJSONResponse({'subreddit': '', 'comments': ''},
headers = response_header)
user_input = params.get('user_input', '****S')
pred = bert_model.predict([user_input])
comments = gpt2_model.generate_comments(user_input = user_input,
top_k = 0,
top_p = 0,
bert_model_prediction = pred,
length = int(params.get('length', 200)),
temperature = float(params.get('temperature', 0.7)))
# comments = list(comments)
generate_count += 1
if generate_count == 8:
# Reload model to prevent Graph/Session from going OOM
tf.reset_default_graph()
sess.close()
sess = gpt2.start_tf_sess(threads = 1)
gpt2_model = GPT2Model(tf_sess = sess)
gpt2_model.load_pretrained_model()
generate_count = 0
gc.collect()
return UJSONResponse({'subreddit': pred, 'comments': comments},
headers = response_header)
if __name__ == '__main__':
uvicorn.run(app, host = '0.0.0.0', port = int(os.environ.get('PORT', 8080)))
A quick overview of how the deployment process works:
Starlette is used for handling the asynchronous API requests to our models. It is a lightweight ASGI framework used for setting up services requiring async requests. However, it requires a working ASGI server (either local or on a cluster) to handle the requests. For this project, we use uvicorn as that server.
The above code is written in a single file app.py and placed in a folder containing the model files. After this, the entire folder is dockerized and ready for deployment on a server/cluster.
The smallest Google Cloud instance (3GB RAM and 1 core) was used to serve the docker container. It will host a 24x7 running docker container with Starlette listening to any POST requests from the website/API.
The API is hosted in the form of a website - https://aditya1702.github.io - where users can write their own Reddit posts and play around with the models. This was inspired by the following open-source GPT2 deployment code - gpt2-cloud-run.
When a POST request is sent to the server/docker container, the input text is extracted from the request header and sent to the models for prediction. The predicted outputs - the classified subreddit and the generated comments - are then sent via a GET request back to be displayed on the website.
All the code is hosted on my Github here and can be reused again. Since the data files were huge, I have not hosted them with the code but they can be easily downloaded from BigQuery with the necessary columns mentioned in this post. This project was a team effort completed with help from my friend Vedant Choudhary - https://vedantc6.github.io.
References
Hugging Face
GPT2-Simple
GPT2-CloudRun
Reddit Data
Google Cloud Platform
Docker
Plotly